Index Lifecycle Management
Features
2.11 Some Design Considerations
1. Overview
Indices don’t have an infinite lifetime like us humans, and they shouldn’t have. They are created, live, and die when their service is appreciated.
Indices need to be managed in favor of performance and stability. An oversized index causes some problems further down the road. Indices’ lifecycles are managed by Index Lifecycle Management (ILM) policies.
Policies decide when to create a new index, rollover an index depending on the configuration, transition of indices from one phase to another such as hot, warm, and cold, and a retention period. So after a while, a determined time period (retention period) an index will be deleted.
2. Basics
Let’s start by making clear some terms and actions.
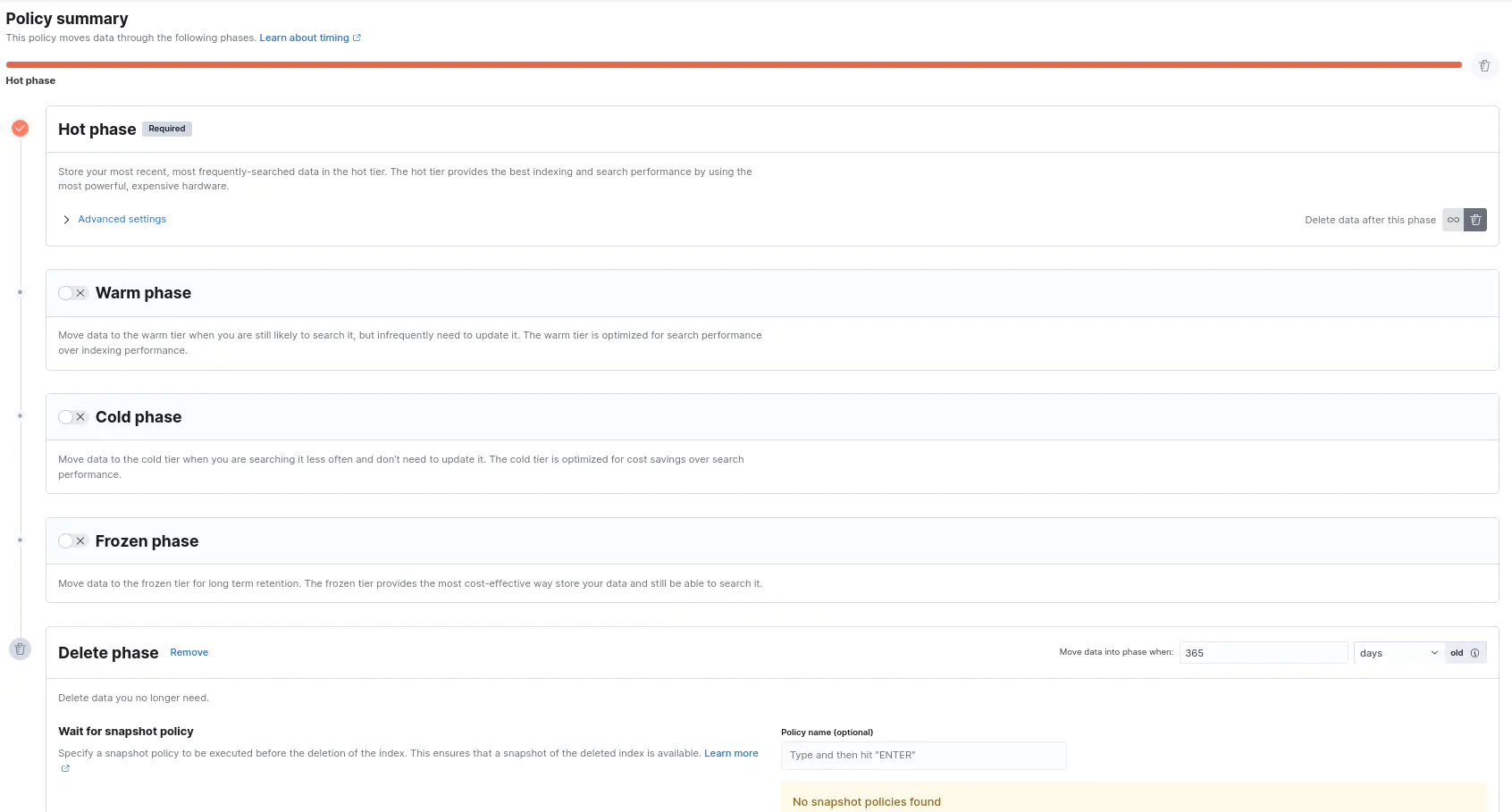
2.1. Phases
Hot: Read and write operations run in this phase. Documents are updated, deleted, created, or queried.
Warm: The index can still be updated but less likely, and can be queried.
Cold: Relative slower queries when compared to hot and warm tiers.
Frozen: The indices which are needed to be searched less frequently than the cold tier in this phase. It takes longer to search this tier than the cold tier. Used for old indices.
Delete: The indices that come to the end of the line will rest their final times in this phase. After their defined retention age they will be gone for good.
Data stream indices automatically use the hot tier
2.2. Segment
-
-
When a query is run in a shard, segments will be queried in order then the results will be combined
-
Immutable
-
Elasticsearch flushes in a while in other words fsyncs the segments so new data can be written to the disk
-
When the documents are indexed, Elasticsearch collects them in RAM and writes them into a new small segment, and every a couple of seconds makes this data can be found as a result of a search but this doesn’t mean that the data has been written to the disk
2.3. Rollover
Further transitions between warm, cold, and delete phases happen due to the time interval of the user’s choice.
The following example has a multi-conditional rollover. The index will be rolled over when it’s 20 days old, or primary shard reaches 20 GB, or the number of documents in the index reaches a million. Depending on which condition is met first, the index will be rolled over on that condition.
PUT _ilm/policy/test-pol
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "20d",
"max_primary_shard_size": "25gb",
"max_docs": 1000000
},
"set_priority": {
"priority": 100
}
},
"min_age": "0ms"
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}
There are a lot of options under the “Advanced settings” tab actually.
Actions can be taken in Kibana UI under the Stack Management > Index Lifecycle Policies tab for a selected policy.
During the hot phase, if searchable snapshot action is taken, in further phases, shrink and force merge actions will not be available to take because force merge should be done in the same phase of the phase before than searchable snapshot action.
2.4. Merge
When a document is updated, the old one is marked as deleted, and a new document is indexed. During the merge operation, documents that are marked as deleted will be deleted.
2.5. Shrink
The indices that are not going to be written can be shrunk to reduce their shard count. Shrink action can be achieved by shrink index API or by an ILM action in the warm phase.
In the hot phase without rollover, the shrink will not be taken into account.
2.6.
Searchable snapshots enable cost savings by freeing us to use replica shards. So how does it achieve this?
As aforementioned, cold and frozen tiers contain infrequently searched data. In cold or frozen tier, an index can be turned into a searchable index by an ILM policy, and by default, it has no replicas.
Indices in the snapshots that have already been taken can be gotten searchable by mounting them. If a snapshot is cloned and then mounted, this will disengage the backup snapshot and searchable snapshot. So they can be managed by ILM policies individually.
Searchable snapshots are searched the same way indices are searched.
When it comes to dealing with old data, searchable snapshots are needed to be borne in mind since old data doesn’t require a fast response most of the time.
If an index is going to be used as a searchable snapshot, it is way better to have each shard single-segmented. Reads are done segment by segment in shards, so fewer segments come with less search time and less snapshot restore time.
When a search is run on a searchable snapshot and relative data to search cannot be found locally, it will be downloaded from the snapshot repository.
In order to run a query on a searchable snapshot, that snapshot needs to be mounted first as an index. This can be done by the user or ILM.
Searchable snapshots indices in a snapshot are restored as they are. There is also a condition: If the original index snapshot is dead, searchable snapshots cannot be restored.
2.7. Fully Mounted Index
The first option is mounting an index fully available in the hot and cold tiers. This operation achieves locally stored, exactly cloned shards of the snapshotted index.
After the fully copied index is created locally, since it copies all of the data residing in the index, search capabilities on this type of mounted indices are reasonably good.
If a search query is run while copying the data locally, the query does not wait until the copy operation is done. It runs alongside the currently running copy operation, but of course, this query will take understandably longer.
These indices survive restarts after being fully copied to the local storage.
2.8. Partially Mounted Index
They are used in the frozen tier to run a search on shared cache data of the snapshotted index. Queries will take longer than a fully mounted index because if the data that is being searched wasn’t searched lately, this means the data is not ready in the cache, so it needs to be retrieved from the snapshot repository.
Infrequently searched data will be released from the cache to cache frequently searched data. As aforementioned, it is cached data, so the data in the cache will not be able to survive after a restart.
2.9. Index Priority
When recovering indices after a restart higher priority indices will be recovered first.
In the design, perspective priority goes with the heat flow. So from higher temperature to lower, it’s meant that the hot phase has higher priority indices than the warm phase, and the warm phase has higher priority indices than the cold phase.
The index priority option is available in hot, warm, and cold phases.
The following ILM policy has hot, warm, cold, frozen, and delete phases. A new index is created in the hot phase with a priority of 200, and when the index reaches 10 GB of primary shard size or becomes 15 days old, it is rolled over to a new index, and then when the index becomes 20 days old, it transitions to the warm phase.
In the warm phase, the index is undergone force merge and shrink. The index is force merged to have only 1 segment, shrunk to have 1 shard, and its priority is set to 100. So it is ready to be a searchable index. When the index becomes 60 days old, it transitions to the cold phase.
In the cold phase, a searchable index is created, and the index is converted into a fully-mounted index, a snapshot repository is defined, and the priority is set to 50. When the index becomes 90 days old, it transitions to the frozen phase.
In the frozen phase, the index is converted into a partially mounted index, and after the index becomes 180 days old, it is sent to its final stop, the delete phase.
In the delete phase index is deleted.
PUT _ilm/policy/my_ilm_policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 200
},
"rollover": {
"max_primary_shard_size": "10gb",
"max_age": "15d"
}
}
},
"warm": {
"min_age": "20d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"set_priority": {
"priority": 100
},
"shrink": {
"number_of_shards": 1
}
}
},
"cold": {
"min_age": "60d",
"actions": {
"searchable_snapshot": {
"snapshot_repository": "test-repo",
"force_merge_index": true
},
"set_priority": {
"priority": 50
}
}
},
"frozen": {
"min_age": "90d",
"actions": {
"searchable_snapshot": {
"snapshot_repository": "test-repo",
"force_merge_index": true
}
}
},
"delete": {
"min_age": "180d",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}
2.10. Wait for Snapshot
This action can be taken in the delete phase and lets a snapshot lifecycle policy take action before the index is gone for good, and the index will be snapshotted.
2.11. Some Desing Considerations
- In ILM policies, it is defined which phases are going to take action and when and what actions the phases are going to trigger
- A longer retention period is more suitable, especially when daily data volume is not big. In this case, a weekly or monthly period is recommended. It ensures to keep the shard size under control
- If the data stream is in variable size, indexing by shard size is better
- Daily index creating is suitable if the retention period is short or if the daily data volume is high
- If the cluster has one node, then replica shards shouldn’t exist. Replica shard setting needs to be set as 0
- It is way better to delete an index than to delete the documents because when the documents are deleted, they are first marked as deleted, but they still use disk space until the merge is run. When the indices are deleted, they are not marked as deleted, they are deleted
- Defining shard size between 10 and 50 GB is a best practice most of the time when efficiency is considered. Search durations, recoveries, and resource consumption are at their optimum in this range.
- Small indices can be combined together by reindex API, and then old small indices can be deleted

0 Comments